4. Data preprocessing
Accessibility computations are based on repeating calculations of the car or transit fastest routes between buildings. These computations demand topologically clean layers of roads and buildings. These layers are supplied by the user and tested and, if necessary, corrected at the beginning of the accessibility study in the Data preprocessing section of the Accessibility Calculator menu (Figure 1). The layers necessary for the visualization of the accessibility calculations are also prepared at this stage.

Figure 1. Data processing section of the Accessibility Calculator menu
There are many types of topological errors and the most frequent for the road network is the lack of a junction at an intersection of two visually overlapping links or two or more links that remain unconnected at a junction. In addition, the attributes of the roads, like traffic directions, can be missing or incomplete. In the case of the layer of buildings, the typical errors include buildings represented by multipart polygons, buildings with holes, and the same building repeated twice or more times. If the layers of roads or buildings are topologically correct, the cleaning procedures will not change them. In this tutorial, we construct topologically correct versions of the road network and buildings and then exploit them to construct three databases – one for computing car accessibility and two for computing transit accessibility for two different versions of the transit networks. Our examples below exploit:
The
gis_osm_roads_freeOSM TAMA road layer, August 2024.The
gis_osm_buildings_a_freeOSM buildings layers for TAMA, August 2024.
It is recommended to open the layers of buildings and roads in your QGIS project before cleaning them and to validate that these are indeed the layers you plan to work with. The clean layers of roads and buildings, as well as the layers built for visualization, are added to your QGIS project.
4.1. Cleaning road network
The road network is cleaned in three steps, applying the v.clean GRASS procedure, see details at https://grass.osgeo.org/grass-stable/manuals/v.clean.html. First, the links’ ends are snapped at junctions. This is done by applying v.clean.snap with the threshold of 1 m: Links’ ends at a distance of 1 m or less from each other will be snapped to one of them. Second, the intersecting links are broken at the points of intersection, and new junctions are created at these points by applying v.clean.break. Third, the overlapping links are revealed and one of them only is preserved by applying v.clean.rmdupl. The cleaning procedure includes a non-topological operation that ensures data consistency. Namely, if one of the fields is chosen as a link ID, the uniqueness of the values in this field is checked. If some values in this field are duplicated or NULL, the repeating or NULL values are substituted by the unique values that are counted from the MAX + 1, where MAX is the maximum value in the chosen field before the test. The user can also choose the option “Create ID” – in this case, a new field link_id is created as the first field in the layer’s attribute table, and filled by the consecutive integer numbers, starting from 0.
Note
The OSM layer of roads contains significant topological errors and the cleaning procedures that we employ in the Accessibility Calculator make this layer topologically consistent. However, it may happen that the layer of roads does not reflect the real structure of the road network. Check the context of your data versus the world maps supplied by QGIS, e.g., versus Google Road maps, and add the missing or delete the excessive links.
To clean the layer of the road links choose Data preprocessing → Clean road network (Figure 2):
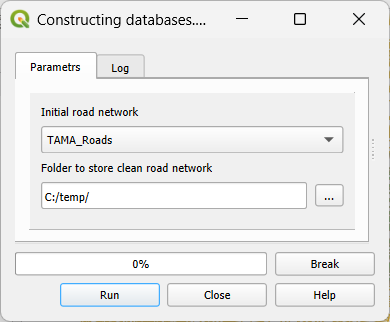
Figure 2. Clean road network dialog
Initial road network - the initial layer of roads that must be a part of the project. All line layers of the project will appear in the list.
id - the unique identifier of a road link.
Folder to store clean road network - the folder to store the clean road layer. The system’s suggestion is a subfolder in the folder where the project is stored with the name that is a concatenation of the name of a project (TAMA) and “_cleaned.” We suggest using this folder for both clean layers of road links and buildings.
Click Run to start. The Progress bar will show the progress of the computations. If something went wrong, you could break the process of dictionary construction by pressing Break. The Log tab contains information about the parameters, information on the process of construction, and the edits that were performed. The clean layer of roads and buildings will be added to the current GIS project. For the example of cleaning the road network and buildings layer of TAMA see section 10.2.
4.2. Cleaning buildings layer
Cleaning of the layer of buildings is performed in four steps. First, the features with the absent (NULL) geometry are deleted from the layer. Second, the multipart features are split into single parts, see https://docs.qgis.org/3.34/en/docs/user_manual/processing_algs/qgis/vectorgeometry.html#qgismultiparttosingleparts, and, in addition, the duplicated features are deleted. Third, duplicated buildings, if they exist, are found and excessive copies are deleted. Fourth, the delete holes algorithm is employed to cover holes in the buildings’ polygons, see https://docs.qgis.org/3.34/en/docs/user_manual/processing_algs/qgis/vectorgeometry.html#qgisdeleteholes. Just as it is done for the road links, the uniqueness of the values chosen as a building ID is tested and if some values in this field are duplicated or NULL, they are substituted by the unique values counted from the MAX + 1, where MAX is the maximum value in the ID field before the test. If the option “Create ID” is chosen, a new field bldg_id is created in the layer’s attribute table and filled by the consecutive integer numbers, starting from 0. To clean the layer of buildings choose Data preprocessing → Clean layer of buildings (Figure 3):
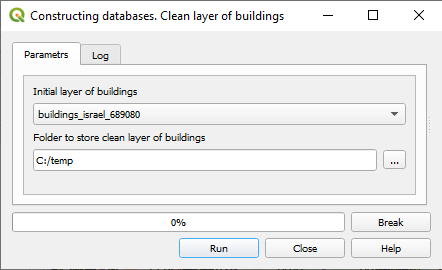
Figure 3. The clean layer of buildings dialog
Initial layer of buildings – the initial layer of buildings that must be a part of the project. All polygon layers of the project will appear in the list.
id – the unique identifier of a building.
Folder to store clean layer of buildings – the folder to store the clean buildings layer. The system’s suggestion is a subfolder in the folder where the project is stored with the name that is a concatenation of the name of a project (TAMA) and “_cleaned.” We suggest using this folder for both cleaned layers of roads and buildings.
Click Run to start. The Progress bar will show the progress of the computations. If something went wrong, you could break the process of dictionary construction by pressing Break. The Log tab contains information about the parameters, information on the process of construction, and the edits that were performed. The clean layer of roads and buildings will be added to the current GIS project. For the example of cleaning the road network and buildings layer of TAMA see section 10.2.
4.3. Preparing layers for visualization
Accessibility Calculator computes travel time to each accessible building and the results are visualized with the thematic maps at the resolution of buildings or lower. Buildings themselves can be used for visualization but, a lion’s share of the constructed area is not covered by the buildings and these maps are inconvenient for the eye. The coverage becomes continuous if buildings are substituted by their Voronoi polygons. These polygons are built based on the building centroids, applying https://docs.qgis.org/3.40/en/docs/user_manual/processing_algs/qgis/vectorgeometry.html#voronoi-polygons algorithm, with the Voronoi polygons’ identifiers repeating identifiers of the buildings. Voronoi polygons are clipped by layer buildings’ centroids buffers of 50m radius, to avoid large Voronoi polygons that always appear at the boundary of the constructed area. In addition to constructing the layer of Voronoi polygons of buildings, the layers of hexagons can be constructed. The defaults are hexagon layers of the 50, 100, 200, 400, and 800 m side lengths. The user-defined layers can be constructed too applying the https://docs.qgis.org/3.40/en/docs/user_manual/processing_algs/qgis/vectorcreation.html#create-grid algorithm. Each layer covers the entire extent of the layer of buildings layer. In each layer, the hexagons that do not overlap any building are deleted and each hexagon has the identifier of the building that is closest to its centroid. If several buildings are at the same distance from the centroid, the minimal identifier is chosen. Note that the same building may be closest to more than one hexagon’s centroids and in this case, these hexagons are dissolved into one. To build layers for visualization choose the Data preprocessing → Build visualization layers (Figure 4):
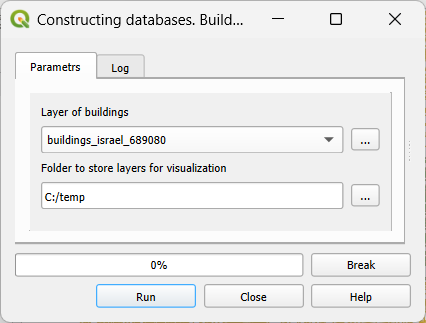
Figure 4. Build visualization layers dialog
Layer of buildings - the cleaned layer of buildings that must be a part of the project. All polygon layers of the project will appear in the list.
Folder to store layers for visualization - the folder to store the layers for visualization. The system’s suggestion is a subfolder in the folder where the project is stored with the name that is a concatenation of the name of a project (TAMA) and “_visio.” We suggest using this folder for all visualization layers.
Click Run to start. The Progress bar will show the progress of the computations. If something went wrong, you could break the process of dictionary construction by pressing Break. The Log tab contains information about parameters and the process of construction. The constructed layers will be automatically added to the current GIS project. Given topologically clean layers of roads and buildings, we can build databases for computing transit and car accessibility and perform accessibility computations. These two parts of the Accessibility Calculator are based on the same data but employ different algorithms, and you can use this plugin for dealing with one of these two components only.